
 for Picture Classification")
%20for%20Image%20Classification_%20Performance%20Benchmarks.png?width=1000&height=556&name=Best%20Vision%20Language%20Models%20(VLMs)%20for%20Image%20Classification_%20Performance%20Benchmarks.png)
{kind=link}
Introduction
Within the quickly evolving subject of synthetic intelligence, the power to precisely interpret and analyze visible knowledge is changing into more and more essential. From autonomous automobiles to medical imaging, the functions of picture classification are huge and impactful. Nevertheless, because the complexity of duties grows, so does the necessity for fashions that may seamlessly combine a number of modalities, akin to imaginative and prescient and language, to attain extra strong and nuanced understanding.
That is the place Imaginative and prescient Language Fashions (VLMs) come into play, providing a strong method to multimodal studying by combining picture and textual content inputs to generate significant outputs. However with so many fashions accessible, how will we decide which one performs finest for a given process? That is the issue we goal to deal with on this weblog.
The first purpose of this weblog is to benchmark Prime Imaginative and prescient Language Fashions on a picture classification process utilizing a primary dataset and examine its efficiency to our general-image-recognition mannequin. Moreover, we are going to display the right way to use the model-benchmark instrument to judge these fashions, offering insights into their strengths and weaknesses. By doing so, we hope to make clear the present state of VLMs and information practitioners in deciding on essentially the most appropriate mannequin for his or her particular wants.
What are Imaginative and prescient Language Fashions (VLMs)
A Imaginative and prescient Language Mannequin (VLM) is a kind of multimodal generative mannequin that may course of each picture and textual content inputs to generate textual content outputs. These fashions are extremely versatile and will be utilized to quite a lot of duties, together with however not restricted to:
- Visible Doc Query Answering (QA): Answering questions primarily based on visible paperwork.
- Picture Captioning: Producing descriptive textual content for photographs.
- Picture Classification: Figuring out and categorizing objects inside photographs.
- Detection: Finding objects inside a picture.
The structure of a typical VLM consists of two fundamental parts:
- Picture Function Extractor: That is often a pre-trained imaginative and prescient mannequin like Imaginative and prescient Transformer (ViT) or CLIP, which extracts options from the enter picture.
- Textual content Decoder: That is sometimes a Massive Language Mannequin (LLM) akin to LLaMA or Qwen, which generates textual content primarily based on the extracted picture options
These two parts are fused collectively utilizing a modality fusion layer earlier than being fed into the language decoder, which produces the ultimate textual content output.
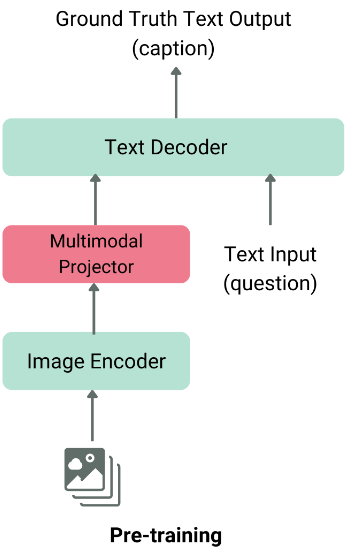
Normal structure of vlm, picture taken from hf weblog.
There are numerous Imaginative and prescient Language Fashions accessible on the Clarifai Platform, together with GPT-4o, Claude 3.5 Sonnet, Florence-2, Gemini, Qwen2-VL-7B, LLaVA, and MiniCPM-V. Attempt them out right here!
Present State of VLMs
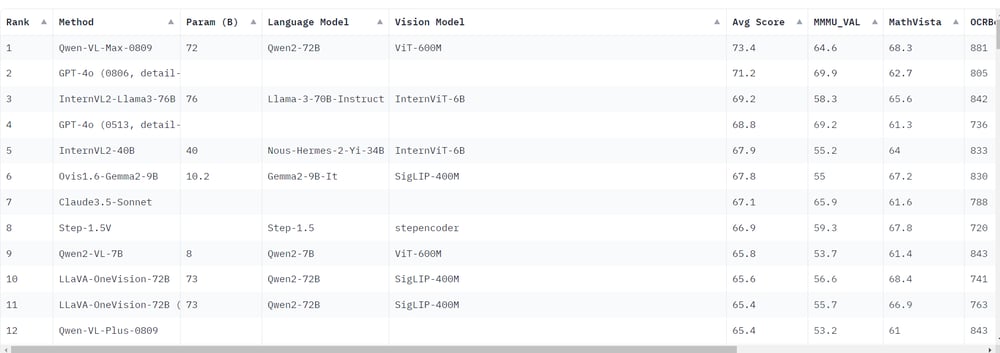
Current rankings point out that Qwen-VL-Max-0809 has outperformed GPT-4O by way of common benchmark scores. That is important as a result of GPT-4o was beforehand thought of the highest multimodal mannequin. The rise of enormous open-source fashions like QWEN2-VL-7B means that open-source fashions are starting to surpass their closed-source counterparts, together with GPT-4o. Notably, Qwen2-VL-7B, regardless of its smaller measurement, achieves outcomes which might be near these of economic fashions.
Experiment setup
{Hardware}
The experiments had been performed on Lambda Labs {hardware} with the next specs:
|
CPU |
RAM (GB) |
GPU |
VRAM (GB) |
|---|---|---|---|
|
AMD EPYC 7J13 64-Core Processor |
216 |
A100 |
40 |
Fashions of Curiosity
We centered on smaller fashions (lower than 20B parameters) and included GPT-4o as a reference. The fashions evaluated embrace:
|
mannequin |
Mmwanness |
|---|---|
|
Qwen/Qwen2-VL-7B-Instruct |
54.1 |
|
openbmb/MiniCPM-V-2_6 |
49.8 |
|
meta-llama/Llama-3.2-11B-Imaginative and prescient-Instruct |
50.7 (CoT) |
|
Llava-HF/Llava-V1.6-Mistral-7B-HF |
33.4 |
|
microsoft/Phi-3-vision-128k-instruct |
40.4 |
|
LLAVA-HF/Llama3-Llava-Subsequent-8B-HF |
41.7 |
|
OpenGVLab/InternVL2-2B |
36.3 |
|
Gpt4o |
69.9 |
Inference Methods
We employed two fundamental inference methods:
- Closed-Set Technique: We utilized commonplace metrics to benchmark these frameworks, together with:
- The mannequin is supplied with a listing of sophistication names within the immediate.
- To keep away from positional bias, the mannequin is requested the identical query a number of occasions with the category names shuffled.
- The ultimate reply is set by essentially the most ceaselessly occurring class within the mannequin’s responses.
- Immediate Instance:
“Query: Reply this query in a single phrase: What sort of object is on this picture? Select one from {class1, class_n}. Reply:
“
- Binary-Based mostly Query Technique:
- The mannequin is requested a sequence of sure/no questions for every class (excluding the background class).
- The method stops after the primary ‘sure’ reply, with a most of (variety of lessons – 1) questions.
- Immediate Instance:
“Reply the query in a single phrase: sure or no. Is the {class} on this picture?“
Outcomes
Dataset: Caltech256
The Caltech256 dataset consists of 30,607 photographs throughout 256 lessons, plus one background muddle class. Every class comprises between 80 and 827 photographs, with picture sizes starting from 80 to 800 pixels. A subset of 21 lessons (together with background) was randomly chosen for analysis.
|
mannequin |
macro avg |
weighted avg |
accuracy |
GPU (GB) (batch infer) |
Velocity (it/s) |
|---|---|---|---|---|---|
|
gpt4 |
0.93 |
0.93 |
0.94 |
N/A |
2 |
|
Qwen/Qwen2-VL-7B-Instruct |
0.92 |
0.92 |
0.93 |
29 |
3.5 |
|
openbmb/MiniCPM-V-2_6 |
0.90 |
0.89 |
0.91 |
29 |
2.9 |
|
Llava-HF/Llava-V1.6-Mistral-7B-HF |
0.90 |
0.89 |
0.90 |
|
|
|
LLAVA-HF/Llama3-Llava-Subsequent-8B-HF |
0.89 |
0.88 |
0.90 |
|
|
|
meta-llama/Llama3.2-11B-vision-instruct |
0.84 |
0.80 |
0.83 |
33 |
1.2 |
|
OpenGVLab/InternVL2-2B |
0.81 |
0.78 |
0.80 |
27 |
1.47 |
|
openbmb/MiniCPM-V-2_6_bin |
0.75 |
0.77 |
0.78 |
|
|
|
microsoft/Phi-3-vision-128k-instruct |
0.81 |
0.75 |
0.76 |
29 |
1 |
|
Qwen/Qwen2-VL-7B-Instruct_bin |
0.73 |
0.74 |
0.75 |
|
|
|
Llava-HF/Llava-V1.6-Mistral-7B-HF_Bin |
0.67 |
0.71 |
0.72 |
|
|
|
meta-llama/Llama3.2-11B-vision-instruct_bin |
0.72 |
0.70 |
0.71 |
|
|
|
general-image-recognition |
0.73 |
0.70 |
0.70 |
N/A |
57.47 |
|
OpenGVLab/InternVL2-2B_bin |
0.70 |
0.63 |
0.65 |
|
|
|
ripe-f/glama3-glava3-8b-hf_bin |
0.58 |
0.62 |
0.63 |
|
|
|
microsoft/Phi-3-vision-128k-instruct_bin |
0.27 |
0.22 |
0.21 |
|
|
Key Observations:
Affect of Variety of Lessons on Closed-Set Technique
We additionally investigated how the variety of lessons impacts the efficiency of the closed-set technique. The outcomes are as follows:
|
mannequin | Variety of lessons |
10 |
25 |
50 |
75 |
100 |
150 |
200 |
|---|---|---|---|---|---|---|---|
|
Qwen/Qwen2-VL-7B-Instruct |
0.874 |
0.921 |
0.918 |
0.936 |
0.928 |
0.931 |
0.917 |
|
meta-llama/Llama-3.2-11B-Imaginative and prescient-Instruct |
0.713 |
0.875 |
0.917 |
0.924 |
0.912 |
0.737 |
0.222 |
Key Observations:
- The efficiency of each fashions typically improves because the variety of lessons will increase as much as 100.
- Past 100 lessons, the efficiency begins to say no, with a extra important drop noticed in meta-llama/Llama-3.2-11B-Imaginative and prescient-Instruct.
Conclusion
GPT-4o stays a powerful contender within the realm of vision-language fashions, however open-source fashions like Qwen2-VL-7B are closing the hole. Our general-image-recognition mannequin, whereas quick, lags behind in efficiency, highlighting the necessity for additional optimization or adoption of newer architectures. The affect of the variety of lessons on mannequin efficiency additionally underscores the significance of fastidiously deciding on the precise mannequin for duties involving massive class units.