

{kind=link}
On this tutorial, we’ll discover easy methods to use Microsoft’s Presidio, an open-source framework designed for detecting, analyzing, and anonymizing personally identifiable data (PII) in free-form textual content. Constructed on prime of the environment friendly spaCy NLP library, Presidio is each light-weight and modular, making it simple to combine into real-time purposes and pipelines.
We are going to cowl easy methods to:
- Arrange and set up the mandatory Presidio packages
- Detect frequent PII entities equivalent to names, telephone numbers, and bank card particulars
- Outline customized recognizers for domain-specific entities (e.g., PAN, Aadhaar)
- Create and register customized anonymizers (like hashing or pseudonymization)
- Reuse anonymization mappings for constant re-anonymization
Putting in the libraries
To get began with Presidio, you’ll want to put in the next key libraries:
- presidio-analyzer: That is the core library answerable for detecting PII entities in textual content utilizing built-in and customized recognizers.
- presidio-anonymizer: This library gives instruments to anonymize (e.g., redact, exchange, hash) the detected PII utilizing configurable operators.
- spaCy NLP mannequin (en_core_web_lg): Presidio makes use of spaCy underneath the hood for pure language processing duties like named entity recognition. The en_core_web_lg mannequin gives high-accuracy outcomes and is really useful for English-language PII detection.
pip set up presidio-analyzer presidio-anonymizer
python -m spacy obtain en_core_web_lgYou would possibly must restart the session to put in the libraries, in case you are utilizing Jupyter/Colab.
Presidio Analyzer
Fundamental PII Detection
On this block, we initialize the Presidio Analyzer Engine and run a primary evaluation to detect a U.S. telephone quantity from a pattern textual content. We additionally suppress lower-level log warnings from the Presidio library for cleaner output.
The AnalyzerEngine hundreds spaCy’s NLP pipeline and predefined recognizers to scan the enter textual content for delicate entities. On this instance, we specify PHONE_NUMBER because the goal entity.
import logging
logging.getLogger("presidio-analyzer").setLevel(logging.ERROR)
from presidio_analyzer import AnalyzerEngine
# Arrange the engine, hundreds the NLP module (spaCy mannequin by default) and different PII recognizers
analyzer = AnalyzerEngine()
# Name analyzer to get outcomes
outcomes = analyzer.analyze(textual content="My telephone quantity is 212-555-5555",
entities=("PHONE_NUMBER"),
language="en")
print(outcomes)
Making a Customized PII Recognizer with a Deny Checklist (Educational Titles)
This code block reveals easy methods to create a customized PII recognizer in Presidio utilizing a easy deny listing, splendid for detecting mounted phrases like tutorial titles (e.g., “Dr.”, “Prof.”). The recognizer is added to Presidio’s registry and utilized by the analyzer to scan enter textual content.
Whereas this tutorial covers solely the deny listing strategy, Presidio additionally helps regex-based patterns, NLP fashions, and exterior recognizers. For these superior strategies, discuss with the official docs: Including Customized Recognizers.
Presidio Analyzer
Fundamental PII Detection
On this block, we initialize the Presidio Analyzer Engine and run a primary evaluation to detect a U.S. telephone quantity from a pattern textual content. We additionally suppress lower-level log warnings from the Presidio library for cleaner output.
The AnalyzerEngine hundreds spaCy’s NLP pipeline and predefined recognizers to scan the enter textual content for delicate entities. On this instance, we specify PHONE_NUMBER because the goal entity.
import logging
logging.getLogger("presidio-analyzer").setLevel(logging.ERROR)
from presidio_analyzer import AnalyzerEngine
# Arrange the engine, hundreds the NLP module (spaCy mannequin by default) and different PII recognizers
analyzer = AnalyzerEngine()
# Name analyzer to get outcomes
outcomes = analyzer.analyze(textual content="My telephone quantity is 212-555-5555",
entities=("PHONE_NUMBER"),
language="en")
print(outcomes)Making a Customized PII Recognizer with a Deny Checklist (Educational Titles)
This code block reveals easy methods to create a customized PII recognizer in Presidio utilizing a easy deny listing, splendid for detecting mounted phrases like tutorial titles (e.g., “Dr.”, “Prof.”). The recognizer is added to Presidio’s registry and utilized by the analyzer to scan enter textual content.
Whereas this tutorial covers solely the deny listing strategy, Presidio additionally helps regex-based patterns, NLP fashions, and exterior recognizers. For these superior strategies, discuss with the official docs: Including Customized Recognizers.
from presidio_analyzer import AnalyzerEngine, PatternRecognizer, RecognizerRegistry
# Step 1: Create a customized sample recognizer utilizing deny_list
academic_title_recognizer = PatternRecognizer(
supported_entity="ACADEMIC_TITLE",
deny_list=("Dr.", "Dr", "Professor", "Prof.")
)
# Step 2: Add it to a registry
registry = RecognizerRegistry()
registry.load_predefined_recognizers()
registry.add_recognizer(academic_title_recognizer)
# Step 3: Create analyzer engine with the up to date registry
analyzer = AnalyzerEngine(registry=registry)
# Step 4: Analyze textual content
textual content = "Prof. John Smith is assembly with Dr. Alice Brown."
outcomes = analyzer.analyze(textual content=textual content, language="en")
for end in outcomes:
print(end result)
Presidio Anonymizer
This code block demonstrates easy methods to use the Presidio Anonymizer Engine to anonymize detected PII entities in a given textual content. On this instance, we manually outline two PERSON entities utilizing RecognizerResult, simulating output from the Presidio Analyzer. These entities characterize the names “Bond” and “James Bond” within the pattern textual content.
We use the “exchange” operator to substitute each names with a placeholder worth (“BIP”), successfully anonymizing the delicate knowledge. That is accomplished by passing an OperatorConfig with the specified anonymization technique (exchange) to the AnonymizerEngine.
This sample might be simply prolonged to use different built-in operations like “redact”, “hash”, or customized pseudonymization methods.
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import RecognizerResult, OperatorConfig
# Initialize the engine:
engine = AnonymizerEngine()
# Invoke the anonymize operate with the textual content,
# analyzer outcomes (probably coming from presidio-analyzer) and
# Operators to get the anonymization output:
end result = engine.anonymize(
textual content="My identify is Bond, James Bond",
analyzer_results=(
RecognizerResult(entity_type="PERSON", begin=11, finish=15, rating=0.8),
RecognizerResult(entity_type="PERSON", begin=17, finish=27, rating=0.8),
),
operators={"PERSON": OperatorConfig("exchange", {"new_value": "BIP"})},
)
print(end result)
Customized Entity Recognition, Hash-Based mostly Anonymization, and Constant Re-Anonymization with Presidio
On this instance, we take Presidio a step additional by demonstrating:
- ✅ Defining customized PII entities (e.g., Aadhaar and PAN numbers) utilizing regex-based PatternRecognizers
- 🔐 Anonymizing delicate knowledge utilizing a customized hash-based operator (ReAnonymizer)
- ♻️ Re-anonymizing the identical values persistently throughout a number of texts by sustaining a mapping of authentic → hashed values
We implement a customized ReAnonymizer operator that checks if a given worth has already been hashed and reuses the identical output to protect consistency. That is significantly helpful when anonymized knowledge must retain some utility — for instance, linking information by pseudonymous IDs.
Outline a Customized Hash-Based mostly Anonymizer (ReAnonymizer)
This block defines a customized Operator referred to as ReAnonymizer that makes use of SHA-256 hashing to anonymize entities and ensures the identical enter at all times will get the identical anonymized output by storing hashes in a shared mapping.
from presidio_anonymizer.operators import Operator, OperatorType
import hashlib
from typing import Dict
class ReAnonymizer(Operator):
"""
Anonymizer that replaces textual content with a reusable SHA-256 hash,
saved in a shared mapping dict.
"""
def function(self, textual content: str, params: Dict = None) -> str:
entity_type = params.get("entity_type", "DEFAULT")
mapping = params.get("entity_mapping")
if mapping is None:
increase ValueError("Lacking `entity_mapping` in params")
# Verify if already hashed
if entity_type in mapping and textual content in mapping(entity_type):
return mapping(entity_type)(textual content)
# Hash and retailer
hashed = ""
mapping.setdefault(entity_type, {})(textual content) = hashed
return hashed
def validate(self, params: Dict = None) -> None:
if "entity_mapping" not in params:
increase ValueError("It's essential to move an 'entity_mapping' dictionary.")
def operator_name(self) -> str:
return "reanonymizer"
def operator_type(self) -> OperatorType:
return OperatorType.Anonymize Outline Customized PII Recognizers for PAN and Aadhaar Numbers
We outline two customized regex-based PatternRecognizers — one for Indian PAN numbers and one for Aadhaar numbers. These will detect customized PII entities in your textual content.
from presidio_analyzer import AnalyzerEngine, PatternRecognizer, Sample
# Outline customized recognizers
pan_recognizer = PatternRecognizer(
supported_entity="IND_PAN",
identify="PAN Recognizer",
patterns=(Sample(identify="pan", regex=r"b(A-Z){5}(0-9){4}(A-Z)b", rating=0.8)),
supported_language="en"
)
aadhaar_recognizer = PatternRecognizer(
supported_entity="AADHAAR",
identify="Aadhaar Recognizer",
patterns=(Sample(identify="aadhaar", regex=r"bd{4}(- )?d{4}(- )?d{4}b", rating=0.8)),
supported_language="en"
)Set Up Analyzer and Anonymizer Engines
Right here we arrange the Presidio AnalyzerEngine, register the customized recognizers, and add the customized anonymizer to the AnonymizerEngine.
from presidio_anonymizer import AnonymizerEngine, OperatorConfig
# Initialize analyzer and register customized recognizers
analyzer = AnalyzerEngine()
analyzer.registry.add_recognizer(pan_recognizer)
analyzer.registry.add_recognizer(aadhaar_recognizer)
# Initialize anonymizer and add customized operator
anonymizer = AnonymizerEngine()
anonymizer.add_anonymizer(ReAnonymizer)
# Shared mapping dictionary for constant re-anonymization
entity_mapping = {}Analyze and Anonymize Enter Texts
We analyze two separate texts that each embrace the identical PAN and Aadhaar values. The customized operator ensures they’re anonymized persistently throughout each inputs.
from pprint import pprint
# Instance texts
text1 = "My PAN is ABCDE1234F and Aadhaar quantity is 1234-5678-9123."
text2 = "His Aadhaar is 1234-5678-9123 and PAN is ABCDE1234F."
# Analyze and anonymize first textual content
results1 = analyzer.analyze(textual content=text1, language="en")
anon1 = anonymizer.anonymize(
text1,
results1,
{
"DEFAULT": OperatorConfig("reanonymizer", {"entity_mapping": entity_mapping})
}
)
# Analyze and anonymize second textual content
results2 = analyzer.analyze(textual content=text2, language="en")
anon2 = anonymizer.anonymize(
text2,
results2,
{
"DEFAULT": OperatorConfig("reanonymizer", {"entity_mapping": entity_mapping})
}
)View Anonymization Outcomes and Mapping
Lastly, we print each anonymized outputs and examine the mapping used internally to keep up constant hashes throughout values.
print("📄 Unique 1:", text1)
print("🔐 Anonymized 1:", anon1.textual content)
print("📄 Unique 2:", text2)
print("🔐 Anonymized 2:", anon2.textual content)
print("n📦 Mapping used:")
pprint(entity_mapping)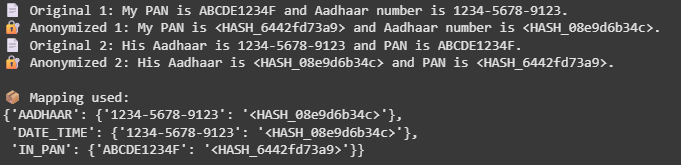
Try the Codes. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter.

I’m a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I’ve a eager curiosity in Information Science, particularly Neural Networks and their utility in numerous areas.
